ARTICLE
ARTICLE
خط چشم انداز رایانه ای ، قسمت 4: استخراج ویژگی
از آموزش عمیق برای سیستم های بینایی توسط محمد الجندی
در این بخش ، ما نگاهی به استخراج ویژگی ها بیندازید - یکی از اجزای اصلی خط لوله بینایی رایانه. فقط کافی است fccelgendy را در جعبه کد تخفیف در هنگام پرداخت در manning.com وارد کنید. ________________________________________________________________________
قسمت 1 را برای معرفی خط لوله دید رایانه ، قسمت 2 را برای مرور کلی تصاویر ورودی و قسمت 3 را برای پیش پردازش تصویر مطالعه کنید.
استخراج ویژگی
استخراج ویژگی یکی از اجزای اصلی خط لوله بینایی رایانه است. در واقع ، کل مدل یادگیری عمیق بر اساس ایده استخراج ویژگی های مفید که به وضوح اشیاء موجود در تصویر را مشخص می کند ، کار می کند. ما زمان بیشتری را در اینجا می گذرانیم زیرا مهم این است که درک کنید ویژگی چیست ، بردار ویژگی ها چیست و چرا ویژگی ها را استخراج می کنیم.
یکی از ویژگی های یادگیری ماشین یک فرد است ویژگی یا ویژگی قابل اندازه گیری پدیده ای که مشاهده می شود. ویژگی ها ورودی ای هستند که به مدل یادگیری ماشین خود وارد می کنید تا یک پیش بینی یا طبقه بندی را تولید کنید. فرض کنید که می خواهید قیمت یک خانه را پیش بینی کنید ، ویژگی های ورودی (خواص) شما ممکن است شامل: مربع_پا ، تعداد_اتاقها ، حمام و غیره باشد و مدل قیمت پیش بینی شده را بر اساس مقادیر ویژگی های شما نشان می دهد. انتخاب ویژگی های خوب که به وضوح اشیاء شما را متمایز می کند ، قدرت پیش بینی الگوریتم های یادگیری ماشین را افزایش می دهد.
ویژگی بینایی رایانه چیست؟
در بینایی رایانه ، یک ویژگی یک قطعه قابل اندازه گیری است داده های موجود در تصویر شما که منحصر به این شیء خاص است. ممکن است یک رنگ متمایز در یک تصویر یا یک شکل خاص مانند خط ، لبه یا بخش تصویر باشد. یک ویژگی خوب برای تشخیص اشیاء از یکدیگر استفاده می شود. به عنوان مثال ، اگر به شما ویژگی ای مانند چرخ بدهم ، و از شما بخواهم حدس بزنید که این وسیله موتورسیکلت است یا سگ. حدس شما چه خواهد بود؟ یک موتور سیکلت. درست! در این مورد ، چرخ یک ویژگی قوی است که به وضوح بین موتور سیکلت و سگ تمایز قائل می شود. اگر همان ویژگی (چرخ) را به شما بدهم و از شما بخواهم حدس بزنید که شی دوچرخه است یا موتورسیکلت. در این مورد ، این ویژگی به اندازه کافی قوی نیست که بین هر دو شیء تمایز قائل شود. سپس باید به دنبال ویژگی های بیشتری مانند آینه ، پلاک ، شاید پدالی باشیم که به طور جمعی یک شی را توصیف می کند.
در پروژه های یادگیری ماشین ، می خواهیم داده های خام (تصویر) را به بردار ویژگی ها تبدیل کنیم. برای نشان دادن الگوریتم یادگیری ما نحوه یادگیری ویژگی های شی.
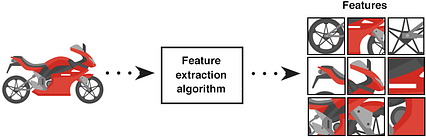
در تصویر بالا ، ما تصویر ورودی خام موتورسیکلت را به الگوریتم استخراج ویژگی تغذیه می کنیم. بیایید الگوریتم استخراج ویژگی را به عنوان یک جعبه سیاه در نظر بگیریم و به زودی به آن باز خواهیم گشت. در حال حاضر ، ما باید بدانیم که الگوریتم استخراج یک بردار تولید می کند که لیستی از ویژگی ها را شامل می شود. به این می گویند بردار ویژگی ها که یک آرایه 1 بعدی است که نمای قوی از شی را ایجاد می کند.
مهم استبرای اعلام اینکه تصویر بالا ویژگی های استخراج شده فقط از یک موتورسیکلت را نشان می دهد. ویژگی بسیار مهم یک ویژگی تکرارپذیری است. همانطور که در ویژگی باید قادر به تشخیص موتور سیکلت به طور کلی نه فقط این یکی خاص. بنابراین ، در مشکلات دنیای واقعی ، این ویژگی یک کپی دقیق از قطعه در تصویر ورودی نخواهد بود.
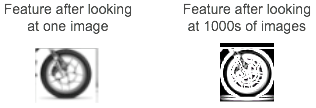
اگر برای مثال ویژگی چرخ را در نظر بگیریم ، این ویژگی دقیقاً شبیه چرخ تنها در یک موتورسیکلت نخواهد بود. در عوض ، به نظر می رسد یک شکل دایره ای با برخی الگوها است که چرخ ها را در همه تصاویر موجود در مجموعه داده آموزشی مشخص می کند. وقتی ویژگی استخراج هزاران تصویر از موتورسیکلت ها را می بیند ، الگوهایی را تشخیص می دهد که به طور کلی چرخ ها را بدون توجه به جایی که در تصویر نشان داده می شود و نوع موتورسیکلت آن مشخص می کند.
چه ویژگی خوب (مفید) می سازد ؟
مدلهای یادگیری ماشین فقط به اندازه ویژگیهایی که ارائه می دهید خوب هستند. این بدان معناست که ارائه ویژگی های خوب یک کار مهم در ساخت مدل های ML است. اما ویژگی خوب آن چیست؟ و چگونه می توانید بگویید؟
بیایید با یک مثال در این مورد بحث کنیم: فرض کنید ما می خواهیم طبقه بندی کننده ای بسازیم تا تفاوت بین دو نوع سگ ، Greyhound و Labrador را تشخیص دهد. بیایید دو ویژگی را در نظر بگیریم و آنها را ارزیابی کنیم: 1) قد سگها و 2) رنگ چشم آنها.

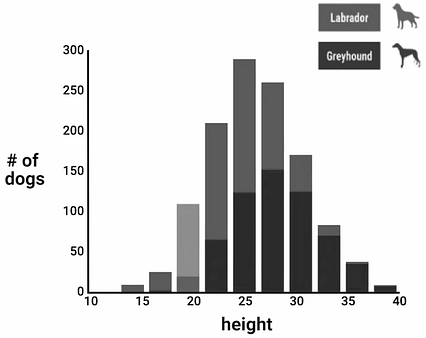
بیایید با ارتفاع شروع کنیم. به نظر شما این ویژگی چقدر مفید است؟ خوب ، به طور متوسط ، تازی ها چند اینچ بلندتر از لابرادورها هستند ، اما نه همیشه. تنوع زیادی در جهان وجود دارد. بیایید این ویژگی را در مقادیر مختلف در جمعیت هر دو نژاد ارزیابی کنیم. ما می توانیم توزیع ارتفاع را بر روی نمونه اسباب بازی در هیستوگرام زیر تجسم کنیم:
 < /img>
< /img> از هیستوگرام بالا ، می بینیم که اگر قد سگ بیست اینچ یا کمتر باشد ، بیش از 80٪ احتمال دارد که این سگ لابرادور باشد. در طرف دیگر هیستوگرام ، اگر به سگهای بلندتر از 30 اینچ نگاه کنیم ، می توانیم کاملا مطمئن باشیم که سگ تازی است. حال ، داده های وسط هیستوگرام (ارتفاع از بیست تا سی اینچ) چطور؟ ما می بینیم که احتمال هر نوع سگ بسیار نزدیک است. فرایند فکر در این مورد به شرح زیر است:
اگر ارتفاع <= 20: احتمال بیشتر را به لابرادور
اگر ارتفاع> = 30: بازگشت احتمال بیشتر به تازی
اگر 20 <ارتفاع> 30: برای طبقه بندی جسم به دنبال ویژگی های دیگر باشید
"قد" سگ در این مورد یک ویژگی مفید است زیرا به تشخیص (افزودن اطلاعات) بین هر دو سگ کمک می کند انواع ما می توانیم آن را نگه داریم ، اما در همه موارد بین Greyhounds و Labradors تمایزی قائل نمی شود ، که خوب است. در پروژه های ML ، معمولاً هیچ ویژگی خاصی وجود ندارد که بتواند همه اشیاء را به تنهایی طبقه بندی کند. به همین دلیل است که با یادگیری ماشین تقریباً همیشه به ویژگی های متعددی نیاز داریم که در آن هر ویژگی نوع متفاوتی از اطلاعات را ضبط می کند. اگر فقط یک ویژگی این کار را انجام دهد ، می توانیم به جای ایجاد مشکل در آموزش طبقه بندی ، دستور if-else را بنویسیم.
مشابهآنچه را که قبلاً با تبدیل رنگ (رنگ در مقابل مقیاس خاکستری) انجام دادیم ، برای فهمیدن اینکه از کدام ویژگی باید برای یک مشکل خاص استفاده کنید ، یک آزمایش فکری انجام دهید. وانمود کنید که طبقه بندی کننده هستید. اگر می خواهید بین تازی و لابرادور تمایز قائل شوید ، چه اطلاعاتی را باید بدانید؟ ممکن است در مورد طول مو یا اندازه بدن ، رنگ و موارد دیگر بپرسید.
یک مثال سریع دیگر از ویژگی های غیر مفید برای هدایت این ایده به خانه. بیایید رنگ چشم را بررسی کنیم. برای این مثال اسباب بازی ، تصور کنید که ما فقط دو رنگ چشم داریم ، آبی و قهوه ای. در اینجا می بینید که هیستوگرام برای این مثال چگونه است:
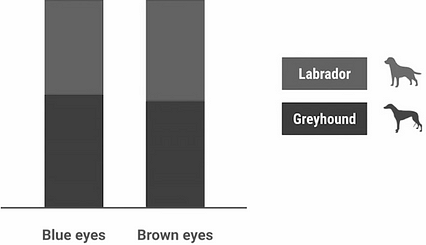 < p> واضح است که برای اکثر مقادیر ، توزیع حدود 50/50 برای هر دو نوع است. عملاً این ویژگی به ما چیزی نمی گوید زیرا با نوع سگ ارتباط ندارد. بنابراین ، بین تازی ها و لابرادورها تفاوتی قائل نمی شود.
< p> واضح است که برای اکثر مقادیر ، توزیع حدود 50/50 برای هر دو نوع است. عملاً این ویژگی به ما چیزی نمی گوید زیرا با نوع سگ ارتباط ندارد. بنابراین ، بین تازی ها و لابرادورها تفاوتی قائل نمی شود. استخراج ویژگی ها (کار دستی در مقابل استخراج خودکار)
خوب ، این می تواند یک موضوع بزرگ در یادگیری ماشین که نیاز به یک کتاب کامل برای بحث دارد. به طور معمول در زمینه موضوعی به نام مهندسی ویژگی توضیح داده می شود. در این بخش ما فقط به استخراج ویژگی ها در تصاویر توجه داریم. من به سرعت این ایده را لمس می کنم.
یادگیری ماشین سنتی از ویژگی های دست ساز استفاده می کند
در مشکلات سنتی یادگیری ماشین ، ما زمان زیادی را در انتخاب ویژگی های دستی صرف می کنیم و مهندسی در این فرآیند ما به دانش حوزه خود (یا مشارکت با متخصصان حوزه) برای ایجاد ویژگی هایی که باعث می شود الگوریتم های یادگیری ماشین بهتر کار کنند ، متکی هستیم. سپس برای پیش بینی خروجی ، ویژگی های تولید شده را به یک دسته بندی مانند Support Vector Machines (SVM) یا Adaboost می دهیم. برخی از مجموعه ویژگی های دست ساز عبارتند از: 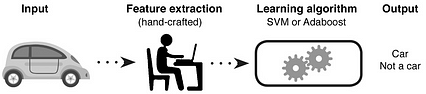
یادگیری عمیق به طور خودکار ویژگی ها را استخراج می کند
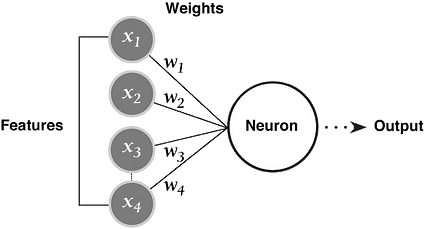
در یادگیری عمیق ، نیازی به استخراج دستی ویژگی ها از تصویر نداریم. شبکه به طور خودکار ویژگی ها را استخراج می کند و با اعمال وزنه به اتصالات خود اهمیت آنها را در خروجی می آموزد. شما تصویر خام را به شبکه تغذیه می کنید و با عبور از لایه های شبکه ، الگوهای درون تصویر را برای ایجاد ویژگی ها مشخص می کند. شبکه های عصبی را می توان به عنوان استخراج کننده های ویژگی + طبقه بندی کننده در نظر گرفت که در مقایسه با مدل های سنتی ML که از ویژگی های دست ساز استفاده می کنند ، قابل آموزش هستند.

چگونه شبکه های عصبی ویژگی های مفید را از ویژگی های غیر مفید تشخیص می دهند؟
شاید این تصور را داشته باشید که شبکه های عصبی فقط ویژگی های مفید را درک می کنند ، اما این کاملا درست نیست. شبکه های عصبی تمام ویژگی های موجود را جمع آوری کرده و وزن های تصادفی به آنها می دهند. در طول فرآیند آموزش ، این وزنه ها را تنظیم می کند تا اهمیت آنها و نحوه تأثیر آنها بر پیش بینی خروجی را منعکس کند. الگوهایی با بیشترین فراوانی ظاهر وزن بیشتری خواهند داشت و به نوبه خود ویژگی های مفیدتری در نظر گرفته می شوند. در حالی که ویژگی هایی با کمترین وزن تأثیر بسیار کمی بر خروجی خواهند داشت. این فرایند یادگیری قرار است با جزئیات بیشتر در فصل بعدی مورد بحث قرار گیرد.
چرا از ویژگی ها استفاده کنیم؟
تصویر ورودیاطلاعات اضافی زیادی دارد که برای طبقه بندی لازم نیست. بنابراین ، اولین قدم پس از پیش پردازش تصویر ، ساده سازی تصویر با استخراج اطلاعات مهم و دور ریختن اطلاعات غیر ضروری است. با استخراج رنگ های مهم یا بخش های تصویر ، می توانیم داده های پیچیده و بزرگ تصویر را به مجموعه کوچکتر از ویژگی ها تبدیل کنیم. این امر کار طبقه بندی تصاویر را بر اساس ویژگی های آنها ساده تر و سریعتر می کند.
مثال زیر را در نظر بگیرید. فرض کنید به ما مجموعه داده ای از 10000 تصویر موتورسیکلت داده می شود که هرکدام 1000 عرض و 1000 ارتفاع دارند. برخی از تصاویر دارای پس زمینه محکم و برخی دیگر دارای پس زمینه مشغول داده های غیر ضروری هستند. وقتی این هزاران تصویر با الگوریتم های استخراج ویژگی تغذیه می شوند ، ما تمام داده های غیر ضروری که برای شناسایی موتورسیکلت ها مهم نیستند را از دست می دهیم و فقط یک لیست تلفیقی از ویژگی های مفید را نگه می داریم که می تواند مستقیماً به طبقه بندی کننده داده شود. این فرایند بسیار ساده تر از این است که طبقه بندی کننده مجموعه داده ای از 10000 تصویر را برای یادگیری خواص موتورسیکلت ها بررسی کند.

فعلا این همه. قسمت 5 را ملاحظه فرمایید ، اگر علاقمند به کسب اطلاعات بیشتر در مورد کتاب هستید ، آن را در liveBook اینجا ببینید و این اسلاید را مشاهده کنید.
ابتدا در https: //freecontent.manning منتشر شده است. com.